SQL Interview Questions & Answers -Part 1 : Introduction
Level : Beginner

Introduction :
Welcome to the first part of my SQL Interview Questions and answers Article series. In this introductory segment, we will explore a variety of questions designed for beginner level SQL candidates. Whether you’re preparing for your first interview or seeking to strengthen your foundational skills, this article will offer valuable insights into common SQL topics and scenarios.
SQL (Structured Query Language) is a powerful tool for managing and manipulating relational databases. It’s used by data analysts, data engineers, software developers, and many other professionals in tech-related fields. This article will cover essential SQL concepts, such as basic queries, table structure, data types, and simple joins. You’ll find examples, explanations, and practical exercises to help you understand these concepts better and apply them in real-world interview situations.
Disclaimer
⬘ The questions and answers covered here are both conceptual and practical. You should practice and solve problems to become a skilled programmer.
⬙ I don’t claim that only these questions are asked during interviews.
Topics Covered :
- Introduction to RDBMS
- Normalisation
- Introduction to SQL
- Tables and Fields
- Constraints
- DDL
- DML & DQL
- Joins
Introduction to RDBMS :
1.What is a database ?
A database is a system for storing and managing data in an organized way. It allows for efficient retrieval, modification, and analysis of information. Databases are used in many applications to maintain data consistency, integrity, and accessibility.
2. What are the different types of databases ?
- Relational Database : Data is stored in tables with rows and columns and is managed in a structured way using SQL. Examples: MySQL, PostgreSQL.
- NoSQL : Flexible databases that can handle unstructured data. Includes key-value, document, and graph databases. Examples: MongoDB, Redis.
Additional databases,
- Graph Database : Graph databases store data in nodes and edges. Graph databases are a good choice for storing data that has relationships between different entities. Example: Neo4j.
- Object-Oriented Databases : These store data as objects, similar to object-oriented programming. They are less common but useful for specific applications.
- Hierarchical databases : Hierarchical databases organize data in a tree-like structure, with a parent-child relationship between records. Hierarchical databases are not as common as other types of databases, but they can be useful for storing data that has a natural hierarchical structure.
3. What is a DBMS ?
A Database Management System (DBMS) is a software system designed to create, manage, and interact with databases. It makes it easy to organize, store, and find information in a structured way. A DBMS provides various functionalities, including data definition, data manipulation, data integrity, and security.
4. What is the difference between a database and a DBMS ?
Here’s a simplified table highlighting the difference between a database and a Database Management System (DBMS):

This table summarizes the main differences between a database and a DBMS, showing how a database is where the data is stored, while a DBMS is the software that helps manage and work with that data.
5. What is RDBMS ?
An RDBMS, or Relational Database Management System, is a type of database system that organizes data into tables with rows and columns. It uses “relations” to connect these tables, typically through primary keys and foreign keys. Primary keys uniquely identify records in a table, while foreign keys link to primary keys in other tables, showing relationships between them.
Popular RDBMS examples include MySQL, PostgreSQL, Oracle, and SQL Server.
6. Name a few popular RDBMS vendors ?
Some popular RDBMS vendors are Oracle, IBM (DB2), Microsoft (SQL Server), MySQL, and PostgreSQL. These companies offer software to help you manage data in tables and handle relationships between them.
7. What is the ACID property in a database ?
The ACID property in a database stands for Atomicity, Consistency, Isolation, and Durability. These four principles help ensure that database transactions work reliably and correctly.
Here’s what they mean,
- Atomicity : The entire transactions takes place at once or doesn’t happen at all.
- Consistency : Database must be consistent before and after execution.
- Isolation : Multiple transactions occur independently without interference.
- Durability : The changes of then successful transaction occurs even if the system faislure occurs.
Normalisation :
- What is Normalisation ?
Normalization is a way to organize a database to make it more efficient and to avoid storing the same information in multiple places. The goal is to reduce redundancy (repeated data) and improve data integrity (accuracy and consistency).
In a normalized database, information is broken down into related tables, and each piece of data is stored only once. This approach reduces the risk of errors when adding, updating, or deleting records because you don’t have to update the same information in multiple places.
2. Why is normalisation necessary ?
Normalization is necessary to ensure data consistency, reduce redundancy, and simplify database maintenance. By organizing data into related tables and defining clear relationships, normalization helps avoid duplication, which minimizes the risk of conflicting or incorrect information.
3. What are the disadvantages of not performing normalisation ?
Data Redundancy : Same information stored in multiple places, leading to higher storage costs and complexity.
Data Inconsistency : Conflicting information due to discrepancies caused by redundant data.
Update Anomalies : Errors during data insertion, updating, or deletion due to redundancy.
Reduced Efficiency : Non-normalized databases require more complex queries, impacting performance.
Maintenance Challenges : Greater effort is needed to maintain consistency and accuracy in non-normalized databases.
4. What are the different normal forms (NF) ?
- 1NF (First Normal Form) : Ensures that each table has unique rows and that each column contains atomic (indivisible) values.
- 2NF (Second Normal Form) : Builds on 1NF, ensuring that all non-key attributes are fully dependent on the primary key, eliminating partial dependencies.
- 3NF (Third Normal Form) : Further refines 2NF by ensuring that all non-key attributes are dependent only on the primary key, not on other non-key attributes, eliminating transitive dependencies.
- BCNF (Boyce-Codd Normal Form) : A stricter version of 3NF that addresses certain anomalies by ensuring that every determinant is a candidate key.
- 4NF (Fourth Normal Form) : Focuses on eliminating multi-valued dependencies, which occur when one attribute in a table has multiple independent values.
- 5NF (Fifth Normal Form) : Addresses cases where a table can be split into smaller tables without losing information, focusing on join dependencies.
These normal forms are designed to reduce redundancy, improve data integrity, and ensure consistency in a database. Each step builds on the previous one to create a more robust and efficient database structure.
5. What is denormalisation ?
Denormalization is a way to make a database faster by adding extra data or combining tables. It helps speed up queries because there are fewer joins and complex structures to deal with. While normalization reduces extra or redundant data, denormalization does the opposite, Tt adds some redundancy to boost performance, often in large databases or data warehouses. This technique can improve speed but might lead to data inconsistency or make the database harder to maintain.
Introduction to SQL :
- What is SQL ?
SQL, which stands for Structured Query Language, is a language used to work with databases. With SQL, you can do things like search for specific data, add new information, update existing data, or delete records. It also lets you create tables, define relationships, and control who can access the database.
2. What is the use of SQL ?
SQL is very popular and is used by most relational databases. It’s the main tool for managing and interacting with data in these databases. If you work with databases, knowing SQL is essential because it helps you do all these tasks easily and consistently.
3. Is SQL a programming language ?
SQL is, fundamentally, a programming language designed for accessing, modifying and extracting information from relational databases. As a programming language, SQL has commands and a syntax for issuing those commands.
4. What are the different parts of SQL ?
SQL has several different parts, each designed for a specific purpose in working with databases:
- DDL (Data Definition Language) : This part is about setting up and changing database structures, like creating or modifying tables, indexes, and views. Common commands include
CREATE,ALTER, andDROP. - DML (Data Manipulation Language) : This is where you change the data in the database. It involves commands like
INSERT,UPDATE, andDELETE. - DQL (Data Query Language) : This part is about retrieving or querying data. The main command is
SELECT. - DCL (Data Control Language) : This deals with who has access to the database and what they can do. Commands here are
GRANTandREVOKE. - TCL (Transaction Control Language) : This part focuses on handling transactions, making sure data stays consistent. Commands include
COMMIT,ROLLBACK, andSAVEPOINT.
These parts of SQL help you work with databases in different ways, whether you’re creating new structures, changing data, retrieving information, managing access, or ensuring that transactions run smoothly.
5. What is DDL ?
DDL, or Data Definition Language, is a part of SQL used to define and manage the structure of a database. It includes commands that let you create, alter, and delete database objects like tables, indexes, and views.
The main DDL commands are:
- CREATE : To create new database objects, such as tables or indexes.
- ALTER : To change existing database objects, like adding a column to a table.
- DROP : To delete database objects.
6. What is DML ?
DML, or Data Manipulation Language, is a part of SQL that deals with changing the data in a database. It includes commands for adding, updating, or deleting data within database tables.
The main DML commands are:
- INSERT : To add new data or records to a table.
- UPDATE : To change existing data or records in a table.
- DELETE : To remove data or records from a table.
7. What is DQL ?
DQL, or Data Query Language, is a part of SQL focused on retrieving data from a database. It’s primarily used to ask questions or run queries to get specific information from the database.
The main DQL command is:
- SELECT : To retrieve data from one or more tables based on certain conditions.
8. What is DCL ?
DCL, or Data Control Language, is a part of SQL that manages who can access a database and what they are allowed to do. It focuses on permissions and security, ensuring that only authorized users have the right access.
The main DCL commands are:
- GRANT : To give specific permissions to users, allowing them to perform certain actions, like reading, writing, or managing database objects.
- REVOKE : To take back permissions from users, limiting what they can do in the database.
8. What is TCL ?
TCL, or Transaction Control Language, is a part of SQL used to manage transactions in a database. Transactions are groups of operations that need to be treated as a single unit, ensuring data integrity and consistency.
The main TCL commands are:
- COMMIT : To save all changes made during a transaction, making them permanent.
- ROLLBACK : To undo changes made during a transaction, reverting the database to a previous state.
- SAVEPOINT : To set a point within a transaction to which you can roll back without affecting the entire transaction.
Tables and Fields :
- What is a Table ?
A table in a database is a structured collection of data organized into rows and columns. Each row represents a record or entry, while each column represents a field or attribute that holds specific information about those records.
2. What is a field in a Table ?
A field in a table is one of the columns where specific information is stored. Each field has a name and a specific type of data, like text, numbers, or dates.
Think of a table as a spreadsheet: each column is a field that describes a particular aspect of a record. For example, in a table of employees, fields might include “Employee ID,” “Name,” “Position,” and “Salary.”
3. Write a SQL command to create a Table ?
To create a table in SQL, you use the CREATE TABLE command. Here's an example that creates a table named "Employees" with several columns, including an ID, name, age, position, and salary :
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
Name VARCHAR(50),
Age INT,
Position VARCHAR(50),
Salary DECIMAL(10, 2)
);4. How do you change the name of a Table ?
To change the name of a table in SQL, you use the ALTER TABLE command with the RENAME TO option. The exact syntax may vary depending on the database system you are using. Here's an example for renaming a table from "Employees" to "Staff":
ALTER TABLE Employees
RENAME TO Staff;5. How to truncate a table ?
records from a table without deleting the table structure itself. It’s a fast way to clear a table because it doesn’t involve individual row-by-row deletions. it simply deallocates the data.
Here’s an example :
TRUNCATE TABLE employees;6. How to drop a table ?
To drop a table in SQL, you use the DROP TABLE command. This completely deletes the table along with all its data, structure, and associated objects, such as indexes and constraints. Unlike truncating, dropping a table is permanent and cannot be undone.
Here's an example of how to drop a table named "employees" :
DROP TABLE Employees;Constraints :
- What is a constraint ?
A constraint in a database is a rule that controls how data is stored or changed. It helps keep the data accurate and consistent.
Here are some common types of constraints :
- Primary Key : Makes sure each record has a unique ID.
- Foreign Key : Connects data between two different tables.
- Unique : Ensures that a column’s values are all different.
- Not Null : Means a column must always have a value, not empty.
- Check : Forces data to meet certain conditions, like age must be above zero.
2. What are the different levels of constraints ?
Constraints in a database can be set at different levels to ensure the data stays accurate and follows the rules.
The two main levels are :
- Column-level Constraints : These constraints apply to individual columns. For example, a
NOT NULLconstraint means the column must always have a value and can't be empty. - Table-level Constraints : These constraints apply to the whole table or multiple columns. For example, a
PRIMARY KEYconstraint can involve more than one column, and aFOREIGN KEYconstraint connects two tables.
3. Give examples of various constraints ?
- Primary Key : Ensures that each row in a table has a unique identifier. For example, an “EmployeeID” column that uniquely identifies each employee.
- Foreign Key : Links two tables based on a shared value. For instance, an “OrderID” in a sales table might refer to an “OrderID” in an orders table.
- Unique : Makes sure all values in a column are different. An example would be a “Username” column where each username must be unique.
- Not Null : Requires a column to always have a value, preventing empty fields. For example, a “FirstName” column that cannot be left blank.
- Check : Sets a rule that data must follow. An example is a “Salary” column with a constraint that requires it to be greater than zero.
4. What is a primary key ?
A primary key is a unique identifier for each row in a database table. It ensures that no two rows have the same value in the primary key column(s). This uniqueness is crucial for distinguishing individual records.
A primary key has two main characteristics :
- Uniqueness : Every primary key value must be unique, ensuring each row is distinct.
- Not Null : A primary key cannot contain null values because it needs to always have a valid identifier.
For example, in an “Employees” table, the “EmployeeID” column might be the primary key,
5. What is a unique key ?
A unique key is a database constraint that ensures all values in a specific column or set of columns are different from each other. It is similar to a primary key, but a table can have multiple unique keys, whereas there’s only one primary key.
Here’s what a unique key does:
- Uniqueness : It guarantees that each value in a unique key column or combination of columns is unique across the table. No duplicate values are allowed.
- Allows Null : Unlike a primary key, a unique key can allow null values, but the non-null values must be unique.
An example would be a “Username” column in a “Users” table, where each username must be unique to prevent duplicate accounts.
6. Difference between a primary key and a unique key ?
Here’s a table that shows the difference between a primary key and a unique key :

7. What is a foreign key ?
A foreign key is a column or a set of columns in a database table that establishes a link to the primary key of another table. It creates a relationship between two tables, ensuring that the data is consistent and connected.
8. What is NULL value ?
A NULL value in a database means “no value” or “unknown.” It indicates that a field doesn’t have any data in it. It’s different from zero or an empty string because those represent known values, while NULL means that there’s nothing assigned to the field.
Here’s what a NULL value represents:
- Missing Data : It shows that no information is provided for a particular column in a specific record.
- Not Zero or Blank : It’s important to remember that NULL is not the same as zero or an empty string — it’s a state of “nothing.”
9. What is NOT NULL constraint ?
A NOT NULL constraint in a database means that a column must always have a value. it can’t be empty or NULL. It ensures that important information is never missing when adding or updating records.
Here’s what it does:
- Requires a Value : You can’t add or update a record with a blank or NULL value in this column.
- Ensures Consistency : By requiring a value, it helps keep the data complete and accurate.
10. Is blank space or Zero (0) same as NULL ?
No, blank space or zero (0) is not the same as NULL in a database. NULL means there’s no value, or it’s unknown. Blank space and zero, however, are values that indicate something specific.
Here’s the difference:
- NULL : It means there’s no data or it’s unknown. It doesn’t represent anything specific.
- Blank Space : This is an empty string, indicating there’s no text, but it’s still considered a value.
- Zero (0) : This is a numeric value, like any other number. It represents the number zero, not an absence of data.
Data Definition Language (DDL) :
- Give some examples of DDL commands ?
DDL (Data Definition Language) commands are a subset of SQL (Structured Query Language) used to define and manage the structure of database objects like tables, indexes, and views. Here are some examples of DDL commands:
CREATE: Creates new database objects such as tables, indexes, views, or databases.
Example :
CREATE TABLE employees (id INT PRIMARY KEY, name VARCHAR(100), age INT);2. Write the syntax for creating a table ?
To create a table in SQL, you use the CREATE TABLE statement. The syntax can vary slightly depending on the SQL database system you are using (e.g., MySQL, PostgreSQL, SQL Server, Oracle, etc.), but the basic structure is generally the same.
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
birth_date DATE,
hire_date DATE NOT NULL,
salary DECIMAL(10, 2) CHECK (salary > 0),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id) 3. How to specify the default value for a column ?
To specify a default value for a column when creating a table, you can use the DEFAULT keyword in your CREATE TABLE statement. This ensures that if a new record is inserted without specifying a value for that column, the default value will be used.
Here’s an example CREATE TABLE query where we set default values for a few columns:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
birth_date DATE,
hire_date DATE DEFAULT CURRENT_DATE, -- Defaults to the current date
salary DECIMAL(10, 2) DEFAULT 30000, -- Default salary is 30,000
department_id INT DEFAULT 1 -- Default department ID is 1
);4. How to specify a foreign key ?
To create a foreign key, you need a column in one table that references the primary key or a unique key in another table. Here’s how to set up a foreign key constraint during table creation and using ALTER TABLE.
CREATE TABLE departments (
department_id INT PRIMARY KEY, -- Primary key for the departments table
department_name VARCHAR(50) NOT NULL
);
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id) -- Foreign key constraint
);5. How to specify a unique key ?
To specify a unique key, you use the UNIQUE constraint in SQL. This constraint ensures that the specified column(s) contain unique values, preventing duplicates.
--When Creating a Table--
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50) UNIQUE, -- No duplicate usernames
email VARCHAR(100) UNIQUE -- No duplicate emails
);
--Adding to an Existing Table--
ALTER TABLE users
ADD UNIQUE (username); -- Adds a unique constraint to the username column
--For Multiple Columns--
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
product_id INT,
UNIQUE (customer_id, product_id) -- Ensures unique combination
);The UNIQUE constraint can be applied during table creation or added later with ALTER TABLE. It can enforce uniqueness on a single column or a combination of columns.
6. How to specify multiple columns as the primary key ?
To specify multiple columns as the primary key, you can define a composite primary key during table creation or with the ALTER TABLE command.
--During Table Creation--
CREATE TABLE orders (
order_id INT,
product_id INT,
PRIMARY KEY (order_id, product_id) -- Composite primary key
);
--Using ALTER TABLE--
ALTER TABLE orders
ADD PRIMARY KEY (order_id, product_id); -- Set composite primary keyIn both cases, the combination of order_id and product_id is unique, forming the composite primary key.
7. What different constraints can you add to a column while creating a table ?
When creating a table, you can apply various constraints to enforce rules and ensure data integrity. Constraints define limitations on the data in the table and specify relationships between tables. Here are the common constraints you can add to a column:
--PrimaryKey--
CREATE TABLE users (
user_id INT PRIMARY KEY -- Unique identifier for each record
);
--Unique--
CREATE TABLE users (
username VARCHAR(50) UNIQUE -- No duplicate usernames
);
--NotNull--
CREATE TABLE employees (
first_name VARCHAR(50) NOT NULL -- This column can't be null
);
--Default--
CREATE TABLE employees (
hire_date DATE DEFAULT CURRENT_DATE -- Default value is today's date
);
--Check--
CREATE TABLE products (
price DECIMAL(10, 2),
CHECK (price > 0) -- Ensures prices are positive
);
--ForeignKey--
CREATE TABLE employees (
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id) -- Reference to another table
);
--AUTO_INCREMENT / IDENTITY--
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY -- Automatically increments for each new row
);8. How to create a copy of a table? (both structure and data) ?
To create a copy of an existing table, including its structure and data, you can use various methods depending on the database system you’re using. Here’s a common approach that works with most SQL databases:
--CREATE TABLE AS SELECT--
CREATE TABLE new_table AS -- Name for the new table
SELECT * FROM existing_table; -- Selects all data from the original table
--CREATE TABLE with LIKE or AS--
-- Clone structure
CREATE TABLE new_table LIKE existing_table; -- Clones the structure without data
--Copy data--
INSERT INTO new_table
SELECT * FROM existing_table; -- Copies the data
--SELECT INTO--
SELECT * INTO new_table FROM existing_table; -- Creates a copy of structure and data9. You have ’n’ tables and asked to create a separate table that will contain a few columns from these tables with data being copied.
Creating a separate table from multiple existing tables with specific columns and copied data requires a bit of planning. You need to select the desired columns from each source table and then combine them into the new table.
The following steps explain how to achieve this :
Example
Let’s consider an example with three tables: employees, departments, and projects. You want to create a new table summary with specific columns from each table.
Source Tables :
employeeswith columns:employee_id,first_name,last_name,department_iddepartmentswith columns:department_id,department_nameprojectswith columns:project_id,employee_id,project_name
New Table :
summaryto include:employee_id,first_name,last_name,department_name,project_name
SQL Statements :
First, create the summary table with the appropriate columns :
CREATE TABLE summary (
employee_id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
department_name VARCHAR(100),
project_name VARCHAR(100)
);Next, insert data into summary by joining the source tables and selecting the required columns :
INSERT INTO summary (employee_id, first_name, last_name, department_name, project_name)
SELECT e.employee_id, e.first_name, e.last_name, d.department_name, p.project_name
FROM employees e
JOIN departments d ON e.department_id = d.department_id
JOIN projects p ON e.employee_id = p.employee_id;10. What is SELECT INTO used for ? (In SQL Server)
In SQL Server, the SELECT INTO statement is used to create a new table and populate it with data from an existing query. This command is particularly useful when you want to quickly create a copy of a table's structure and data, or when you need to create a new table from a subset of data.
Key Features of SELECT INTO :
- Creates a New Table : The
SELECT INTOstatement creates a new table with the structure based on the source query's selected columns. - Copies Data : It populates the new table with the data returned by the source query.
- Quick Setup : It automatically creates columns with appropriate data types based on the selected data.
Usage Examples :
--Creating a Table from an Existing Table--
SELECT * INTO backup_table
FROM original_table; -- Creates a complete copy of 'original_table' with all data
--Creating a Table with Specific Columns--
SELECT employee_id, first_name, last_name
INTO employee_summary
FROM employees; -- Creates 'employee_summary' with selected columns
--Creating a Table with Filtered Data--
SELECT * INTO high_salary_employees
FROM employees
WHERE salary > 60000; -- Creates 'high_salary_employees' with only employees earning over 60,00011. Difference between ALTER and RENAME ?
The ALTER and RENAME commands in SQL are used for different purposes. Here's a concise explanation of their functions and when to use them, structured as a table for clarity :
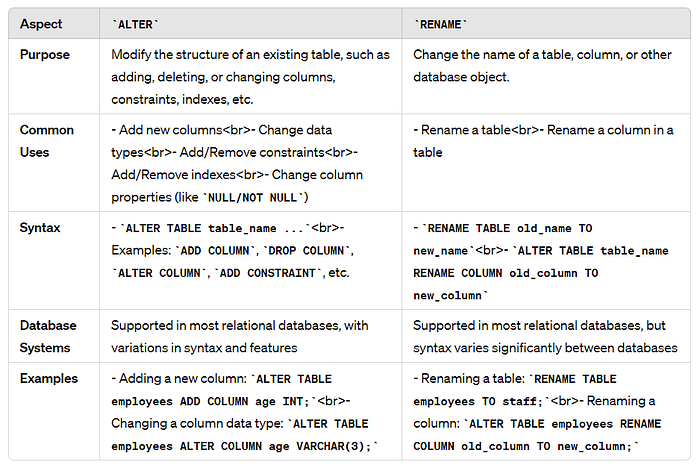
12. Can a previously nullable column be altered to a NOT NULL column ? If so, explain the steps.
Yes, you can alter a previously nullable column to a NOT NULL column in SQL. However, before making this change, you need to ensure that no existing records in the table have NULL values in that column. Otherwise, the operation will fail.
The process generally involves a few key steps :
Ensure No NULL Values in the Column : Before changing the constraint to NOT NULL, you need to ensure that there are no NULL values in the column. You can do this by querying the table to identify any NULL values.
SELECT * FROM your_table WHERE your_column IS NULL;Update NULL Values : If the column contains NULL values, you should update them with appropriate default values or other non-null values.
UPDATE your_table SET your_column = 'default_value' WHERE your_column IS NULL;Alter the Column to NOT NULL : Once there are no NULL values in the column, you can change its constraint to NOT NULL.
ALTER TABLE your_table ALTER COLUMN your_column data_type NOT NULL;DML & DQL :
- How do you insert rows into a table ?
To insert rows into a table, you use the SQL INSERT INTO statement. You specify the table name, the column names, and the values you want to insert.
For example, to add a new row to a "Customers" table, you would write something like:
INSERT INTO Customers (FirstName, LastName, Age) VALUES ('John', 'Doe', 30);2. What are the different syntaxes for inserting records into a table ?
There are a few common syntaxes for inserting records into a table in SQL :
Specifying Columns and Values :
You can list the columns where you want to insert data and then specify the corresponding values.
Example :
INSERT INTO Employees (FirstName, LastName, Age) VALUES ('Alice', 'Smith', 28);Inserting Without Specifying Columns :
If you insert into all columns in the correct order, you don’t need to list the column names.
Example :
INSERT INTO Employees VALUES (1, 'Bob', 'Johnson', 35);Inserting Multiple Rows at Once :
You can insert multiple records in a single query by separating each set of values with commas.
Example :
INSERT INTO Employees (FirstName, LastName, Age)
VALUES ('Carol', 'Davis', 29),
('David', 'Wilson', 40);Inserting from a Select Statement :
You can insert records from another table using a SELECT statement.
Example :
INSERT INTO Employees (FirstName, LastName, Age)
SELECT FirstName, LastName, Age FROM Applicants WHERE Status = 'Hired';3. What is the syntax to insert multiple records at a time ?
To insert multiple records at a time, you can use a single INSERT INTO statement with multiple sets of values, separated by commas.
Here's the basic syntax :
INSERT INTO Employees (FirstName, LastName, Age)
VALUES
('John', 'Doe', 30),
('Jane', 'Smith', 28),
('Mike', 'Johnson', 35);4. How to update data in a table ?
To update data in a table, you use the UPDATE statement. It allows you to change specific values in one or more rows, usually with a WHERE clause to specify which rows to update.
Here's the basic syntax :
UPDATE Employees SET Age = 32 WHERE EmployeeID = 101;5. How to delete a row in a table ?
To delete a row in a table, you use the DELETE statement with a WHERE clause to specify which row(s) you want to remove.
Here's the basic syntax :
DELETE FROM Employees WHERE EmployeeID = 101;6. Difference between DELETE and TRUNCATE ?
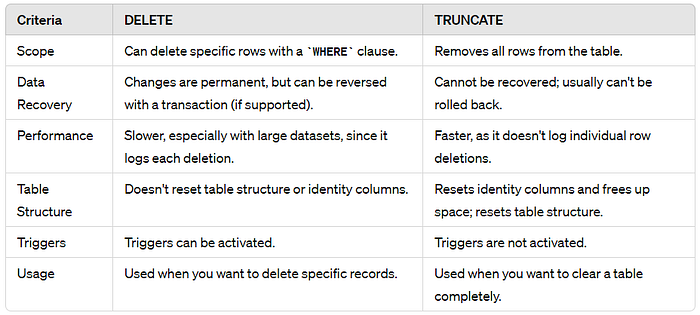
7. Explain how DML operations are performed on a View or Are Views used only for SELECT queries ?
Views are primarily used for SELECT operations, but DML (data manipulation language) operations like INSERT, UPDATE, and DELETE can be performed under certain conditions.
- Simple Views: DML works on views referencing a single base table with no joins, aggregations, or complex logic.
INSERT INTO DeptView (DeptName, Location) VALUES ('Marketing', 'New York');- WITH CHECK OPTION: This clause ensures modifications align with the view’s definition, but adds complexity.
CREATE VIEW ActiveEmployees AS
SELECT * FROM Employees WHERE Active = 'Y'
WITH CHECK OPTION;
-- Attempt to update someone to inactive through the view (fails)
UPDATE ActiveEmployees SET Active = 'N' WHERE EmployeeID = 123;- INSTEAD OF Triggers: Complex views can use triggers to translate DML operations into actions on the underlying tables.
CREATE TRIGGER update_total_sales
INSTEAD OF UPDATE ON TotalSales
FOR EACH ROW
BEGIN
-- Update logic here to modify underlying tables based on the view's definition
END;8. How to fetch rows from a table ?
To fetch rows from a table, you use the SQL SELECT statement. It allows you to specify which columns you want to retrieve and apply conditions to filter the results.
Here's the basic syntax :
Get all rows from an “Employees” table :
SELECT * FROM Employees;Get specfic columns from an “Employee” table :
SELECT FirstName, LastName FROM Employees;Get specific rows from an “Employee” table based on a condition :
SELECT * FROM Employees WHERE Age > 30;Get all rows from an “Employee” table with sorting :
SELECT * FROM Employees ORDER BY LastName;9. What is a query condition? How to write it in SQL ?
A query condition is a part of a SQL statement that specifies which rows to include in the query result. It’s often used in the WHERE clause to filter data. Conditions use operators like =, >, <, >=, <=, <>, and others to compare values.
Equality :
SELECT * FROM Customers WHERE City = 'New York';Inequality :
SELECT * FROM Products WHERE Price <> 100;Greater Than or Less Than :
SELECT * FROM Employees WHERE Age > 30;Multiple Conditions :
SELECT * FROM Orders WHERE OrderDate >= '2023-01-01' AND OrderDate <= '2023-12-31';In summary, a query condition helps you define the criteria for filtering rows in a SQL query. You write it in the WHERE clause and use various operators to create the condition.
10. How to sort the fetched records ?
To sort fetched records, you use the ORDER BY clause in a SQL query. This clause lets you specify which column(s) to sort by and the sorting order (ascending or descending).
Ascending Order :
By default, ORDER BY sorts in ascending order (ASC). For example, to sort employees by age in ascending order, you'd write :
SELECT * FROM Employees ORDER BY Age;Descending Order :
To sort in descending order, you use DESC. For example, to sort employees by age in descending order, you'd write :
SELECT * FROM Employees ORDER BY Age DESC;Multiple Columns :
You can sort by multiple columns. The following example sorts by department and then by age within each department :
SELECT * FROM Employees ORDER BY Department, Age;11. What is grouping ? How to write in SQL ?
Grouping in SQL is a way to organize data into sets based on common values in specific columns. It allows you to perform aggregate calculations like SUM(), COUNT(), AVG(), MAX(), or MIN() on each group.
Here’s an example :
Grouping by a Single Column : This query groups employees by their department and counts the number of employees in each group.
SELECT Department, COUNT(*) FROM Employees GROUP BY Department;Grouping by Multiple Columns : This query groups employees by both department and job title, then calculates the average salary for each group.
SELECT Department, JobTitle, AVG(Salary) FROM Employees GROUP BY Department, JobTitle;In summary, grouping in SQL helps you organize data into distinct sets based on specified columns, allowing you to apply aggregate functions on these groups. You do this with the GROUP BY clause, followed by one or more columns to define the grouping.
12. How to find how many records are being fetched ? Or How to calculate count of records ?
To find out how many records are being fetched, you can use the COUNT() function in SQL. This function returns the number of rows that meet certain conditions.
Here's how you might use it :
Counting All Records : This counts all rows in a table.
SELECT COUNT(*) FROM TableName;Counting with a Condition : This counts the number of employees older than 30.
SELECT COUNT(*) FROM Employees WHERE Age > 30;Counting Grouped Records : This counts how many employees are in each department.
SELECT Department, COUNT(*) FROM Employees GROUP BY Department;So, to find out how many records are being fetched, you generally use the COUNT() function, either to count all rows or to count rows that meet specific criteria.
13. How to find the maximum and minimum value for a field in fetched records ?
To find the maximum and minimum values for a field in fetched records, you can use the MAX() and MIN() functions in SQL. These functions return the highest or lowest value for a specific column.
Here’s how you can use them :
Find the Maximum Value : This finds the maximum salary from all employee records.
SELECT MAX(Salary) FROM Employees;Find the Minimum Value : This finds the minimum salary from all employee records.
SELECT MIN(Salary) FROM Employees;Find Both Maximum and Minimum Together : This query retrieves both the highest and lowest salary from the “Employees” table.
SELECT MAX(Salary) AS Highest, MIN(Salary) AS Lowest FROM Employees;Max and Min with a Condition : This example finds the maximum salary for employees in the IT department.
SELECT MAX(Salary) FROM Employees WHERE Department = 'IT';In summary, to find the maximum or minimum value for a field in fetched records, you can use the MAX() and MIN() functions, either individually or together, and with or without specific conditions.
14. How to sum values in a field for all records ?
To sum values in a field for all records, you can use the SQL SUM() function. This function adds up all the values in a specified column.
To sum the “Salary” field for all employees : This will return the total sum of all employee salaries.
SELECT SUM(Salary) FROM Employees;To sum the “Salary” field based on condition : This example sums the salaries of employees in the “Sales” department.
SELECT SUM(Salary) FROM Employees WHERE Department = 'Sales';In summary, to sum values in a field for all records, you use the SUM() function. If needed, you can also use a WHERE clause to apply conditions to select which records to include in the sum.
Joins :
- What is a join in SQL ?
A join in SQL is a way to combine rows from two or more tables based on a related column. It lets you pull together data that’s spread across different tables to get the results you need.
2. What are the different types of joins ?
The main types of SQL joins are :
- Inner Join : Returns rows where the data matches in both tables.
- Left Join (or Left Outer Join) : Returns all rows from the left table and matching rows from the right table.
- Right Join (or Right Outer Join) : Returns all rows from the right table and matching rows from the left table.
- Full Join (or Full Outer Join) : Returns all rows when there’s a match in either table.
- Cross Join : Returns the Cartesian product, pairing every row from one table with every row from the other.
3. What is Inner Join ?
An inner join is a type of SQL join that returns only the rows where there is a match in both tables based on a specified condition. If there’s no match, the row is not included in the result. This join is used when you want to find common data between two tables.
4. What is Left Outer Join ?
A left outer join, or simply a left join, is a type of SQL join that returns all the rows from the left table and only the matching rows from the right table. If there’s no match, the result still includes the row from the left table, but the corresponding columns from the right table will contain null values. It’s used when you want to keep all data from the left table, even if there’s no matching data in the right table.
5. What is Right Outer Join ?
A right outer join, or right join, is a type of SQL join that returns all the rows from the right table and only the matching rows from the left table. If there’s no match, the row from the right table is still included, but the corresponding data from the left table is null. This join is used when you want to keep all data from the right table, even if there’s no matching data in the left table.
6. What is Full Outer Join ?
A full outer join, or full join, is a type of SQL join that returns all rows from both the left and right tables. If there’s a match, the data from both tables is combined. If there’s no match, the result still includes the row from one table with nulls for the missing values from the other table. This join is used when you want to see all data from both tables, whether or not there’s a match.
7. What is Cross Join ?
A cross join, also known as a Cartesian product, is a type of SQL join that returns every combination of rows between two tables. It doesn’t require a common column or a matching condition. If one table has 3 rows and the other has 4, the cross join will produce 12 results. It’s useful when you need to pair every row from one table with every row from the other.
8. What is a Self Join ?
A self join is a type of SQL join where a table is joined with itself. You use aliases to differentiate the instances of the table in the query. This is useful when you want to find relationships within the same table, like an employee who reports to another employee in a company.
9. What is Equi Join ?
An equi join is a type of SQL join where you join two tables based on equality in a specified column or set of columns. Essentially, it returns rows where the values in the specified columns are the same in both tables. It’s the most common type of join and is often used in inner joins and other join types when you need to find matching data.
10. What is Natural Join ?
A natural join is a type of SQL join where two tables are joined based on columns with the same name and data type in both tables. It automatically matches these columns without specifying them explicitly in the query. It can be a quick way to join tables, but you need to be cautious because if the tables have unexpected common columns, it might lead to incorrect results or ambiguity.
11. Explain semi-join ?
A semi-join is a type of SQL join that returns rows from one table where there’s at least one matching row in another table, but it doesn’t include the matching rows from the other table. Essentially, it’s like a filter — you get rows from one table that have related data in the other table. This is useful when you only need to know which rows meet a condition, without pulling in the data from the other table.
12. Explain anti-join ?
An anti-join is a type of SQL join that returns rows from one table where there’s no matching row in another table. It’s like the opposite of a semi-join — it gives you rows from the first table that don’t meet the join condition in the second table. This is useful when you want to find records in one table that are not in another, such as finding users with no orders or products with no sales.
13. Given a query in Cross Join, convert it into an Inner Join ?
To convert a cross join into an inner join, you need to add a condition that specifies how the tables should be related. With a cross join, every row from one table is paired with every row from another, resulting in a Cartesian product. An inner join, on the other hand, connects rows based on a common condition or key.
Suppose you have a cross join query like this :
SELECT * FROM table1 CROSS JOIN table2;To convert it into an inner join, you need to specify a condition that joins the two tables on a common column.
Here’s an example :
SELECT * FROM table1 INNER JOIN table2 ON table1.common_column = table2.common_column;This change limits the output to rows where there is a matching value in the specified column, reducing the number of results from the Cartesian product to just those with matching keys.
14. Given a query in Right Outer Join, convert it into a Left Outer Join ?
To convert a query from a right outer join to a left outer join, you can swap the order of the tables and adjust the join condition accordingly. A right outer join keeps all rows from the right table, while a left outer join keeps all rows from the left table.
Here’s an example of a right outer join :
SELECT * FROM table1 RIGHT JOIN table2 ON table1.id = table2.id;To convert this into a left outer join, you just switch the order of the tables and keep the same join condition :
SELECT * FROM table2 LEFT JOIN table1 ON table2.id = table1.id;15. Convert an Inner Join into an Equi Join ? or What is required to convert an Inner Join into an Equi Join ?
An inner join and an equi join can be very similar, but the key difference is that an equi join specifically joins tables based on equality between specified columns. An inner join can have different join conditions (like using inequalities or custom expressions), while an equi join uses strict equality.
To convert an inner join into an equi join, you’d need to ensure that the join condition uses an equality operator (=) between specific columns in both tables. If your inner join already has this kind of condition, it's effectively an equi join.
Here’s an example of an inner join :
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.ref_id;This query is already an equi join because it uses an equality condition to join the tables. If your inner join uses something other than = (like <, >, !=, etc.), you'd need to modify the condition to use = to convert it into an equi join.
16. What should be taken care of to improve the performance of queries containing Joins ?
To improve the performance of queries with joins, consider these key factors:
- Indexes : Ensure the columns used in joins have indexes to speed up data retrieval.
- Primary and Foreign Keys : Use primary keys and foreign keys to maintain relationships and optimize joins.
- Query Optimization : Avoid unnecessary joins and ensure you’re joining only the columns you need.
- Data Volume : Consider reducing the size of the data set by applying filters before the join.
- Execution Plan : Analyze the execution plan to understand how the database processes the join and identify any bottlenecks.
- Database Design : Use normalized database design to reduce data redundancy and simplify joins.
- Avoid Cross Joins : Unless needed, avoid cross joins, which can lead to a large Cartesian product and slow queries.
- Use Aliases : Use table aliases to clarify joins and improve query readability.
If you’re new to databases and want to learn the basic fundamentals, you can explore this link for a comprehensive introduction.
